https://tech.kakaoenterprise.com/157
대화 속에 드러나는 감정을 분석해드립니다!
시작하며 안녕하세요, 카카오엔터프라이즈에서 오픈 도메인 대화 모델을 기획하고 있는 프링과 쌔미입니다. 오늘은 저희가 다른 곳과는 차별화된 감정 분석 모델을 개발한 이야기를 소개하려
tech.kakaoenterprise.com
kakaoenterprise, Pring and Sammy, 2022.09.28
카카오엔터프라이즈에서 오픈 도메인 대화 모델을 기획하고 있는 분들께서 감정 분석 모델에 대한 포스트를 작성해서 이걸 리뷰해보려 한다. 사실 이 글을 읽기 전에는 카카오워크라는 업무용 메신저가 따로 있는지도, 카카오톡에서 AI와 대화를 할 수 있는 '외개인아가'라는 채널이 있는지도 몰랐다.
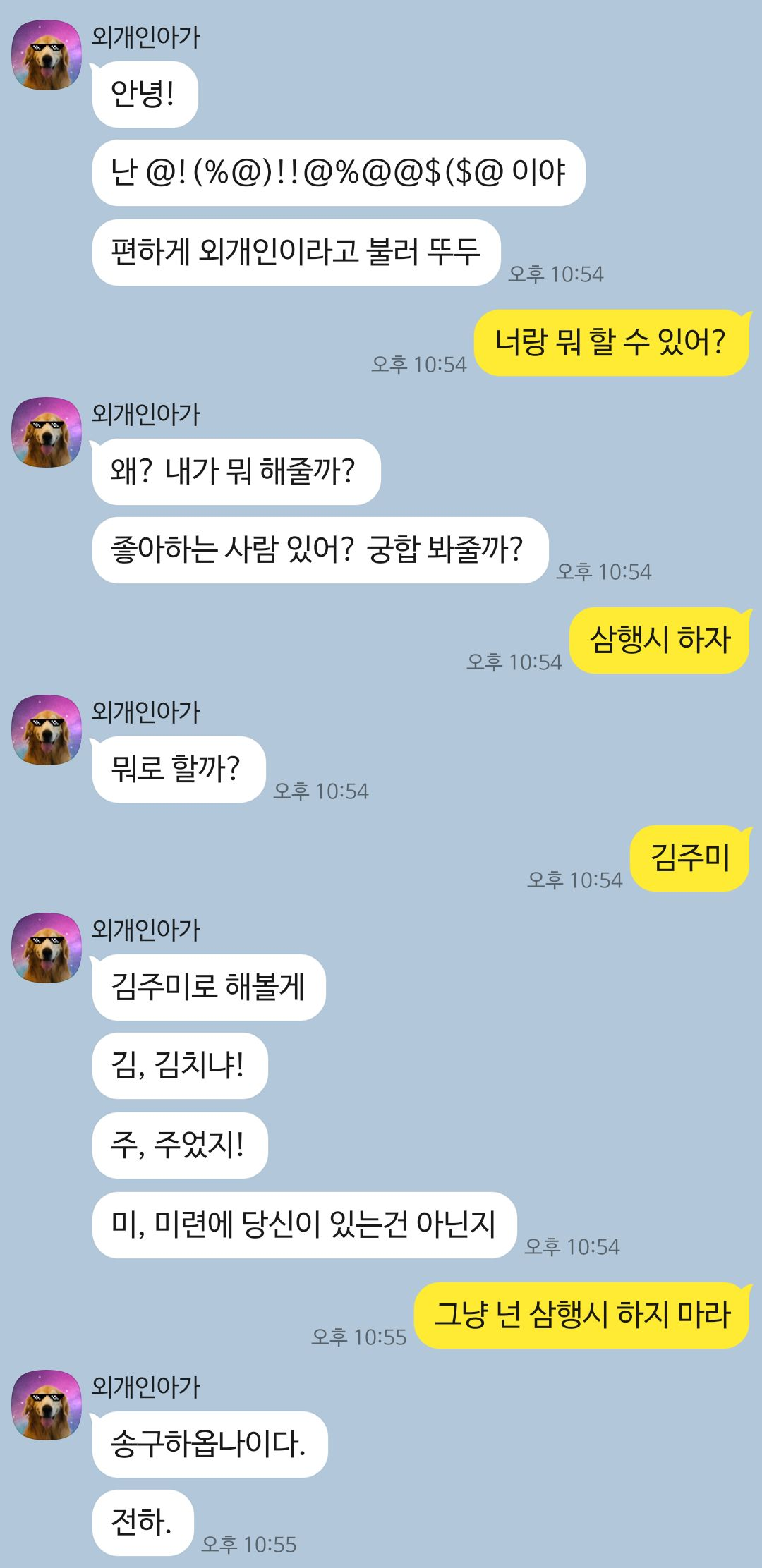
시험삼아 해봤는데 생각보다 엄청 발랄한 외개인이 나와서 놀랐다...
맥락 상으로 알맞은 답문을 출력하는 AI는 상당 수 구현이 되어있지만, 대화 데이터 속에서 맥락 상의 감정을 분간하여 적절한 반응을 하는 모델을 만들고 싶어서 감정 모델을 처음 만들게 되셨다는데... 정말 멋있다. 보통은 그러면 좋겠다~고 생각하고 끝날 텐데 그걸 실제로 옮기고 성공해내는 열정이 대단하게 느껴졌다.
감정의 분류
감정 모델은 대화의 맥락을 읽기 위해서 단일 발화를 기반으로 학습시키는 게 아닌, A-B 두 화자가 나누는 '대화 데이터'를 기반으로 학습시키는 것으로 시작한다. 이건 기본적인 데이터 수집 방법이고, 가장 중요한 작업은 '감정의 유형을 나누는 것'이다.
- Positive(긍정)
- Negative(부정)
- Ambiguous(미묘함)
- Neutral(감정없음)
고려사항
-Negative(부정)의 감정을 민감하게 추출해낼 것. 사람들은 부정적인 감정을 가졌을 때 봇에게 더 예민하게 반응하기 때문
-감정 유형은 상호 배타적이지 않음. 감정은 분류되지 못하고 미묘하게 겹치는 부분이 생기기 마련. -> 다중 태깅
-같은 문장일지라도 대화 문맥(상황)에 따라 다른 감정값을 추출해낼 수 있음.

본문에 나오는 맥락 상의 다른 감정 설명 예시이다.
이렇듯 분류 기준을 정확하게 나누었지만 이 맥락 상의 감정을 분류하기는 정말 고된 작업이었을 것이다. 고려사항에 있는 것처럼 감정이라는 건 같은 문장일지라도 대화 문맥에 따라 다른 감정이 담겨있을 수 있다. 특히 카카오톡 같은 메신저의 경우에는 수집되는 데이터가 문장형으로 종결되는 것이 아닌 단편적인 구어들이다보니 최소 3~4 개의 대화가 이어져야 한다. AI 데이터 수집도 참... 대규모 노동이다.
감정 분석 모델의 적용
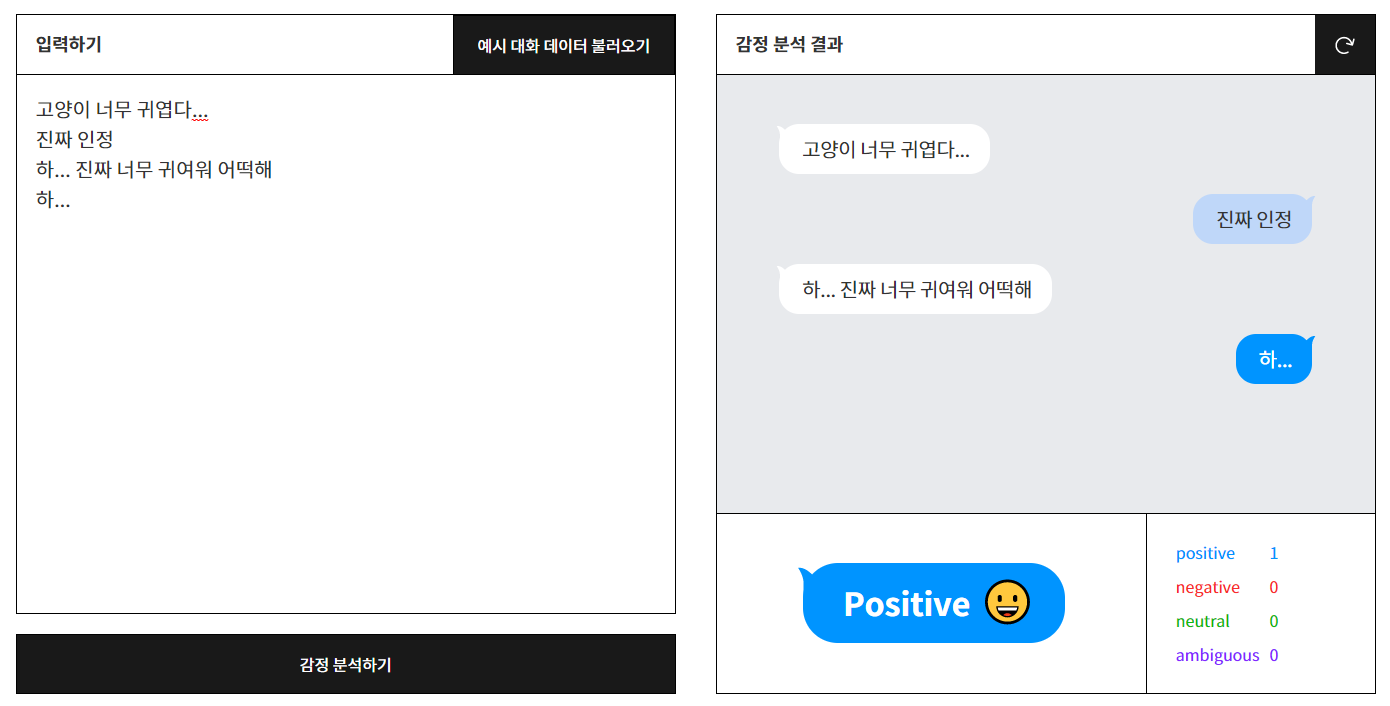
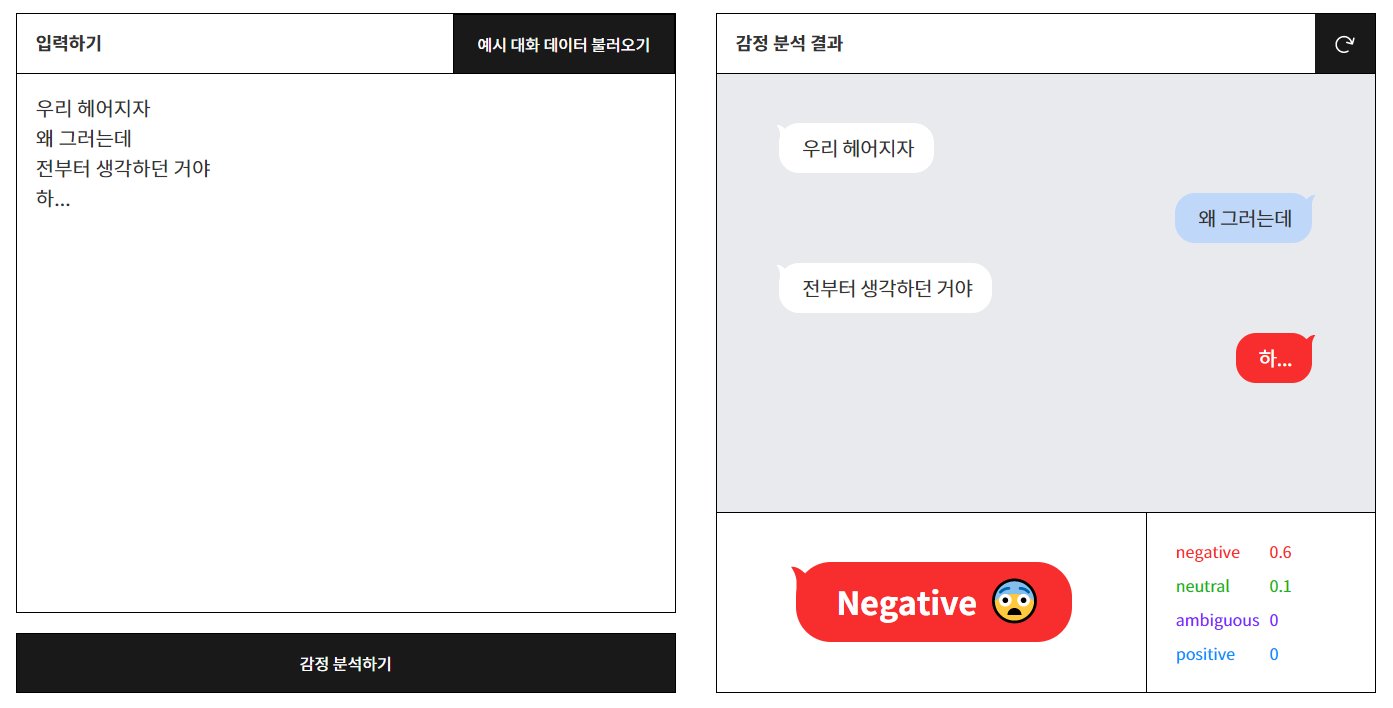
이렇듯 감정의 분류를 거쳐 만들어진 모델을 적용한 AI는 같은 문장이라도 다른 감정을 포착해낼 수 있다! '헤어지자'/'고양이 너무 귀엽다'로 첫 문장을 나눠서 "하..."에 대한 다른 감정을 포착할 수 있는지 테스트해봤다. 하단에 감정의 구성 정도를 알 수 있게 해준다. 사이트를 올려놓으니 심심하면 한 번 테스트해보는 걸 추천한다!
https://labs.kakaoi.ai/emotion
테크그라운드
AI Lab 개발자들이 만들어 나가고 있는기술 데모를 선보이는 공간입니다.AI를 더하여 일상을 새롭게~
labs.kakaoi.ai
또한 이 감정 분석 모델을 카카오톡 챗봇 '외개인아가'에게도 적용시켰다.
챗봇의 답변에 감정이 담겨있다면, 그 감정에 알맞는 이모지를 랜덤으로 붙이는 것이다.
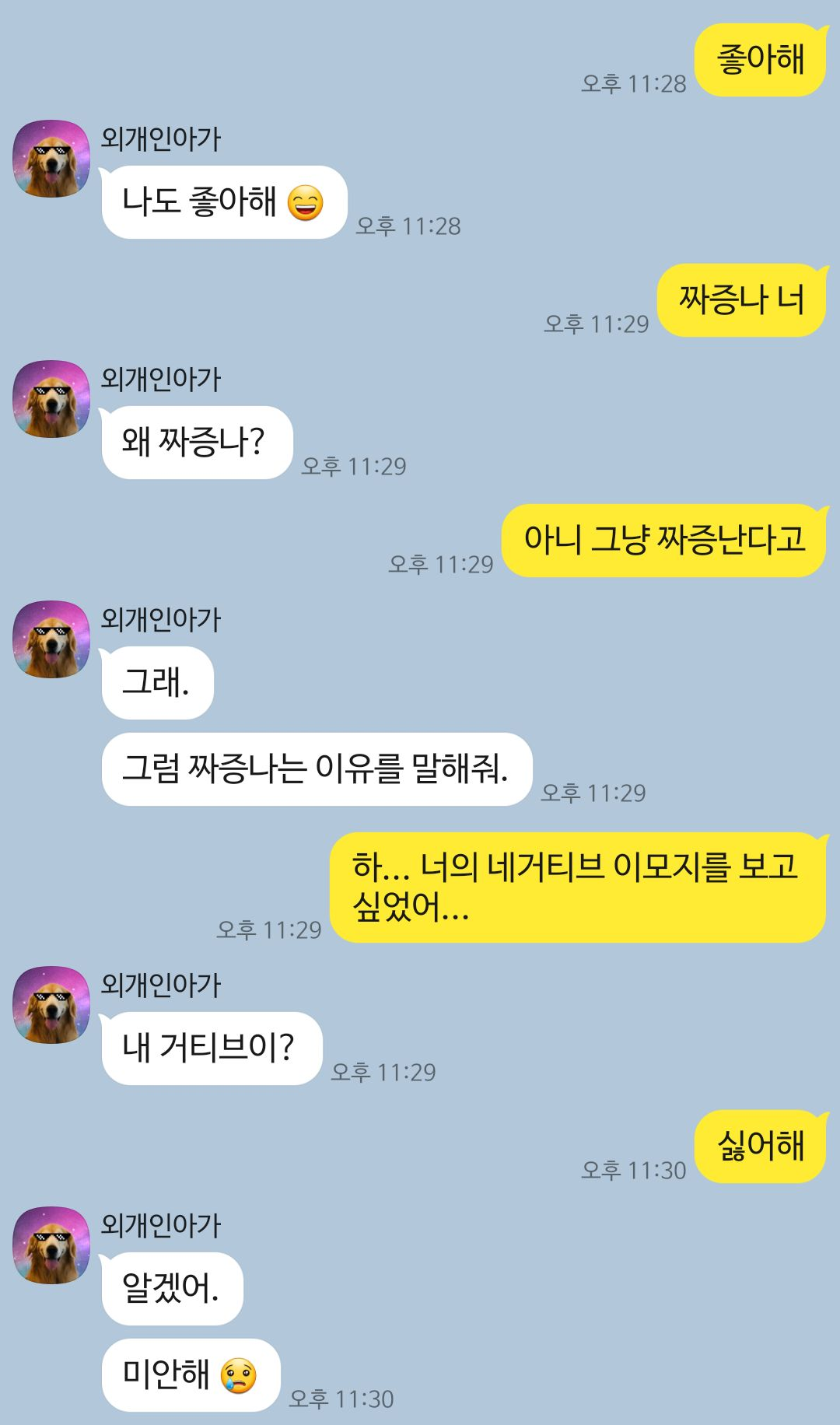
시험 삼아 외개인 아가에게 Positive와 Negative를 끌어낼 수 있는 대화를 걸어보았는데 정말 이모지가 붙어서 나왔다.
똑똑하고 귀여운 아이라 테스트만 하려고 했는데 정이 들 것 같다 . . .
(감정 분석 모델을 이용해 반응을 다각화하고 이모지를 붙이기 시작한 이후로 대화 지속 비율이 늘었다는 통계도 있다!)
추후 계획 : 감정 모델 고도화
감정 모델은 현재 카카오톡의 챗봇에게도 적용되어 있지만, 앞으로도 더욱 고도화시켜나갈 계획이라고 한다.
첫째는 당연히 감정 레이블을 할 수 있는 데이터를 많이 수집하는 것이고, (카카오톡 챗봇 외개인아가를 시작할 때 해당 대화 내역이 챗봇의 학습에 이용될 수 있다는 동의를 먼저 받는다.) 둘째는 수집된 데이터를 다양한 각도에서 볼 수 있도록 라벨링 작업을 이어나가는 것, 마지막으로 Ambiguous(미묘함) 감정이 Positive(긍정)에 가까운지 Negative(부정)에 가까운지 모델을 고도화 시키는 것이 과제로 남아있다. 현재까지 라벨링 된 데이터 중 감정없음(Neutral)이 59.7%지만, 애매하다는 이유로 분류된 미묘함(Ambiguous)도 3.4%로 절대 적은 숫자가 아니니 이것만으로도 감정 모델의 정확도가 더 높아질 것으로 기대된다.
! 용어 정리 !
NLP(natural language processing, 자연어 처리) : 자연어는 우리가 일상에서 사용하는 언어를 말하고, 이 자연어를 처리하는 행위를 말하는 NLP는 이러한 자연어의 의미를 분석하여 컴퓨터가 처리할 수 있도록 하는 일이다.
코퍼스(corpus) : 번역하면 '말뭉치'나 '말모음' 등으로 연구를 염두에 두고 구축된 글 또는 말 텍스트를 모아놓은 것이다.
멀티턴(Multi-turn) 세션 데이터 : 두 번 이상 일련의 대화로 이루어진 데이터
'기타 > 기술스터디' 카테고리의 다른 글
| [기술스터디] 2022년 IT Trend 돌아보기 (1) | 2023.01.18 |
|---|---|
| [기술스터디] 인터넷, 웹 3.0으로의 진화 (0) | 2023.01.10 |
| [기술 스터디] 로우 코드(Low Code)와 노코드(No code) (0) | 2022.11.22 |
| [기술스터디] Cheapfake(Shallowfake)란 무엇일까요? (118) | 2022.11.15 |
| [기술 스터디] 2022년 3분기, 통계로 살펴본 가장 위협적인 악성코드는? (112) | 2022.11.01 |



